最近,我想我应该重新审视自己在读研以来,在机器学习的征途上的学习经历了。整天沉迷在一个一个的网络里面,都忘了它本来应该是干什么的。
从一个当时自认为写代码很6的码农,曾经一度认为自己的一生将与程序相伴终生了,虽然现在对编程还是挺感兴趣,但并不会作为终生事业为之奋斗了,它已经成为一个基本能力,一种为了更高精神诉求服务的基本能力了。想想从码农走到机器学习这条道上还是满辛苦的,高数不太好,英语有点烂。我是不是能为广大的码农走上机器学习提供点帮助呢?
一、机器学习是什么?
机器学习是什么?我想我应该去翻一本文献,给出一个定义,而这个定义与技术本身无关,因为好像在以前,我还是自认为自己是个码农的时候,机器学习的概念就与技术、数学等等无关,而现在虽然扎根其中,却对它仍然无法描述,它好像仍然与技术无关,更贴近数学。
二、学习的起点
我在回忆自己是从什么地方开始学习的。从一本书《集体智慧编程》,从这本书开始的,与其说是入门机器学习,不如说在分析代码。分析了好久的Python代码,对,期间还写了个Python的搜索引擎的小程序,虽然与机器学习无关,好在是数据搜集和处理阶段应该做的工作。对于编程人员可能更希望使用Python或者你自己熟悉的语言边写机器学习的代码,这样能更好的掌控自己的代码、自己的算法,但是我认为这完全没必要较这个真。我推荐的还是先从Matlab入手,原因两个:1,代码多,资源广;2.工具好用,Matlab运行完成会保留下来所有的变量,我们可以很容易查看,不需要像C、C++、C#、java、Python似的,需要调试才能看到。很多需要在其它语言里写好多的,在Matlab里很简单。学习嘛,不需要讲求说代码整体运行速度怎样,懂得了道理,并且实现了功能就好啦,做底层优化不是学习阶段应该干的事情。我从前用C#写过一次KNN,就再也不愿意自己动手写了,可能我们学习算法原理需要两个小时,但是要想敲出来可能需要半天,再调试,一天过去了。
题外话:如果我们在什么技术论坛上说:XX语言是世界上最好用的编程语言。那非炸锅不可。但是我经常会向开始学习编程的人推荐首先学习C#,因为工具--VS是真的好用,特别是对于初学者。每种语言都有其自身的历史使命,就像人一样。如果机器学习入门,我推荐Matlab。
三、两种距离
3.1皮尔森相关
第一个真正意义上的了解其作用的函数或者方程应该叫皮尔森相关系数(Pearson correlation coefficient)(有人会跟我纠正是皮尔逊不是皮尔森,简直有病),这个可以用来描述线性相关程度的函数,对这个线性相关性的更深刻的理解也是前段时间反刍的时候看《概率论与数理统计》——在“协方差与相关系数”那一节。
相关系数=两个向量的协方差/(各自标准差的积);
非要看公式就要去搜索了:
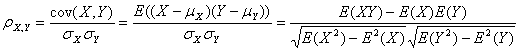
理解这个相关系数,我们就要回到高中数学,正态分布,标准差、方差、均值(期望)。
协方差是什么呢?
博客园的这篇文章可能讲的还是比较靠谱的:http://www.cnblogs.com/ywl925/archive/2013/07/24/3210822.html
但是无论怎样都不如自己拿着高等数学书看个通透。
协方差的计算过程形如方差,但是在对样本自身进行减期望后,需要进行平方,而协方差就把第二个因数用另一个样本的自身减均值来代替。然后在求相关系数的时候,除以的却是(两样本标准差的积)。如果将第二个样本看作第一个样本,也就是认为两者其实就是同一个样本,那么化简出来其实协方差就是方差,相关系数等于1。那也就是说,如果两个样本完全一样,系数=1。如果不一样,系数的绝对值会<1,还有负相关的情况。要不要思考下,相关系数的绝对值怎么就不能>1呢?书上有证明。
3.2欧几里德距离
人们会尊称它为欧氏距离,说白了呢:就是空间中两点之间的距离,等于两点各轴向的坐标值对应相减后平方,再相加。仍然是中学数学,不要担心自己理解不了,比理解皮尔森系数简单多了。我或许应该将它俩掉个个来讲,但我就这么讲了,没道理。如果是二维坐标系下的点,你会怎么求两点之间的距离呢?相减---平方----相加---开根号。三维的呢?N维的呢?照此办理,绝无差错。在以后的岁月里,你机会任何地方都能看到欧氏距离的身影,所以记住它,它就是那么简单,但是应用很广。
4.协同过滤
下面我觉得我们应该学习一下协同过滤。图书推荐、课程推荐、电影推荐、音乐推荐之类的。自己去搜去看。
就是说什么呢?我们两个都是喜欢阅读的人,而期间恰好我看过的书呢,你也看过,我们都给了个评分。是不是说我们看的书相同的越多我们的阅读兴趣就越相同呢?那如果不仅看的相同的书多,而且评分还差不多,那接下来是不是就可以把你看过但是我没看过的书,推荐给我了呢?同样的,我看过你却没看过的书,我也可以推荐给你。这个任务交给算法。大概就是这么个流程:
- 先讲讲数据库:书表、人表、评分表,评分表关联书表ID和人表的ID。
- 程序先select 书ID——从评分表——where 两个人(两个样本,X/Y)都看过的书,就是书ID相等 并且 人ID等于第一个人ID或等于第二个人ID。
- 然后把这些书ID的两个人的评分都拿出来形成一个矩阵。这个矩阵的每一行代表一本书,每一列代表一个人对那些书的评分。这样无论你用上面的哪种距离都可以算出两个人的距离来。你可以认为每行(每本书)代表一个维度,评分就是在那个维度上的坐标值
- 接着就是算每两个人的距离。然后对这些距离进行排序,距离越小的说明他俩兴趣越相同。距离最相同的两个人你就可以互相推荐书了!或者单拿出一个人,找跟他距离最小的那个人。